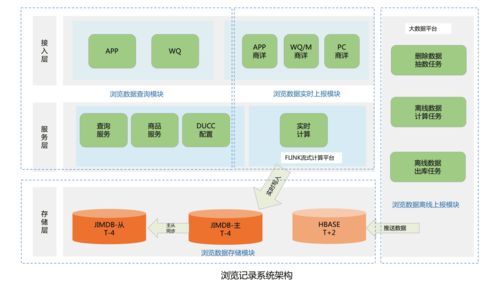
京東云技術(shù)團隊在處理海量用戶數(shù)據(jù)時,面臨瀏覽記錄的高并發(fā)寫入和實時查詢的巨大挑戰(zhàn)。針對每日百億級別的瀏覽記錄,我們設(shè)計并實現(xiàn)了一套高效、可靠的實時數(shù)據(jù)處理與存儲系統(tǒng)。
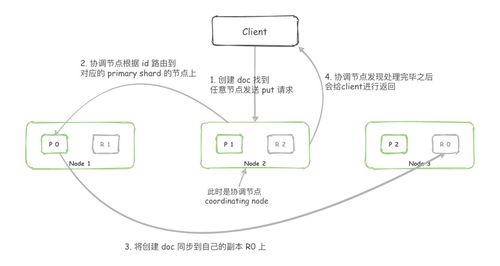
系統(tǒng)架構(gòu)分為數(shù)據(jù)采集、實時處理和存儲服務(wù)三個核心模塊。在數(shù)據(jù)采集層,我們采用分布式消息隊列(如Kafka)進行日志收集,確保高吞吐量的數(shù)據(jù)攝入,同時通過負載均衡機制分散寫入壓力,避免單點故障。在實時處理層,我們利用流計算框架(例如 Apache Flink)進行數(shù)據(jù)清洗、去重和聚合操作。通過窗口計算和狀態(tài)管理,系統(tǒng)能夠?qū)崟r分析用戶行為,提供低延遲的查詢響應(yīng)。在存儲服務(wù)層,我們結(jié)合了多種存儲方案:使用 NoSQL 數(shù)據(jù)庫(如 HBase)存儲原始瀏覽記錄,支持水平擴展以應(yīng)對數(shù)據(jù)增長;采用緩存技術(shù)(例如 Redis)加速熱點數(shù)據(jù)的訪問,并通過分布式文件系統(tǒng)備份歷史數(shù)據(jù),確保數(shù)據(jù)持久性和可恢復(fù)性。
在實現(xiàn)過程中,我們注重優(yōu)化數(shù)據(jù)處理管道,減少網(wǎng)絡(luò)延遲和I/O瓶頸。例如,通過數(shù)據(jù)分區(qū)和索引策略提升查詢效率,并實施監(jiān)控告警機制,實時跟蹤系統(tǒng)性能。該系統(tǒng)已成功應(yīng)用于京東電商平臺,支持秒級的數(shù)據(jù)寫入和查詢,日均處理百億條記錄,保證了用戶體驗和業(yè)務(wù)決策的實時性。我們將繼續(xù)探索AI驅(qū)動的數(shù)據(jù)優(yōu)化方法,進一步提升系統(tǒng)的智能化和擴展能力。