在 Elasticsearch 中,使用 PUT 請求存儲一條數(shù)據(jù)(即索引一個文檔)是一個涉及多個組件的復(fù)雜過程,它不僅包括數(shù)據(jù)的存儲,還涵蓋了數(shù)據(jù)處理、路由、復(fù)制等一系列服務(wù)。下面我們將詳細解析從發(fā)起 PUT 請求到數(shù)據(jù)最終落地的完整流程。
1. 客戶端發(fā)起請求
用戶通過 REST API 向 Elasticsearch 集群發(fā)送一個 PUT 請求,其基本格式為:PUT /<index>/_doc/<id>。其中 <index> 是目標索引名稱,<id> 是指定的文檔 ID(如果省略,Elasticsearch 會自動生成一個)。請求體包含了要存儲的 JSON 格式文檔數(shù)據(jù)。
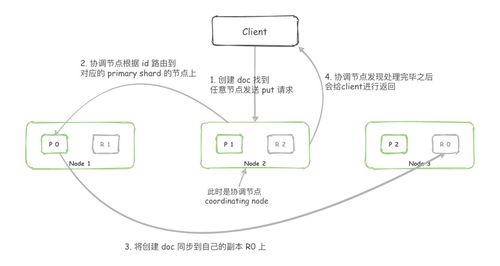
2. 請求到達協(xié)調(diào)節(jié)點
Elasticsearch 集群中的任意節(jié)點都可以接收請求,這個節(jié)點被稱為“協(xié)調(diào)節(jié)點”。協(xié)調(diào)節(jié)點負責處理客戶端的請求,并將其路由到正確的數(shù)據(jù)節(jié)點。它首先會解析請求,檢查索引是否存在、映射是否定義等。如果索引是自動創(chuàng)建的(根據(jù)配置),協(xié)調(diào)節(jié)點會觸發(fā)索引的創(chuàng)建過程。
3. 文檔路由與主分片定位
Elasticsearch 索引由一個或多個主分片(及可選的副本分片)組成。協(xié)調(diào)節(jié)點根據(jù)文檔 ID 計算其應(yīng)該存儲在哪個主分片上。默認的路由算法是:shard<em>num = hash(</em>routing) % num<em>primary</em>shards,其中 _routing 默認為文檔 ID。通過計算,協(xié)調(diào)節(jié)點確定目標主分片及其所在的數(shù)據(jù)節(jié)點(稱為“主分片節(jié)點”)。
4. 轉(zhuǎn)發(fā)請求到主分片節(jié)點
協(xié)調(diào)節(jié)點將索引請求轉(zhuǎn)發(fā)到上一步確定的主分片節(jié)點。此時,主分片節(jié)點開始本地的索引處理流程。
5. 本地索引處理(數(shù)據(jù)處理階段)
在主分片節(jié)點上,數(shù)據(jù)會經(jīng)歷一系列處理步驟:
- 解析與驗證:系統(tǒng)解析 JSON 文檔,驗證其結(jié)構(gòu)。
- 字段映射與類型轉(zhuǎn)換:根據(jù)索引的映射(mapping)定義,對字段進行類型處理。例如,將字符串日期轉(zhuǎn)換為
date類型,或?qū)ξ谋咀侄芜M行分詞設(shè)置。如果字段未預(yù)先定義且動態(tài)映射開啟,Elasticsearch 會自動推斷其類型并更新映射。 - 分析過程:對于文本字段(
text類型),會調(diào)用相應(yīng)的分析器(analyzer)進行分詞、過濾(如小寫化、去除停用詞等),生成倒排索引所需的詞項。 - 生成文檔數(shù)據(jù)結(jié)構(gòu):處理后的文檔會被轉(zhuǎn)換為內(nèi)部存儲結(jié)構(gòu),包括源文檔(
_source,默認存儲原始 JSON)、倒排索引條目、文檔值(用于排序和聚合)等。
6. 寫入事務(wù)日志與內(nèi)存緩沖區(qū)
為確保數(shù)據(jù)的持久性和一致性,Elasticsearch 采用了以下步驟:
- 事務(wù)日志(Translog)寫入:在數(shù)據(jù)真正寫入磁盤前,操作會首先被記錄到事務(wù)日志中。Translog 提供了崩潰恢復(fù)機制,防止數(shù)據(jù)丟失。
- 內(nèi)存緩沖區(qū):文檔數(shù)據(jù)被添加到索引的內(nèi)存緩沖區(qū)中,此時尚不可被搜索。
7. 刷新(Refresh)與可搜索性
內(nèi)存緩沖區(qū)會定期刷新(默認每 1 秒一次,可通過 refresh_interval 配置)。刷新過程會:
- 將內(nèi)存緩沖區(qū)中的內(nèi)容寫入一個新的段(segment)中,這是一個輕量級的提交。
- 重新打開索引,使得新段內(nèi)的文檔變得可搜索。
注意:刷新操作不會立即將數(shù)據(jù)持久化到磁盤,而是先寫入文件系統(tǒng)緩存,速度較快。
8. 副本同步(存儲支持服務(wù)的關(guān)鍵)
如果索引配置了副本分片(replica shards),主分片節(jié)點在本地處理完成后,會將索引請求并行轉(zhuǎn)發(fā)到所有副本分片所在的節(jié)點。副本分片執(zhí)行相同的本地索引處理流程。只有當所有副本分片也成功完成操作后(或根據(jù)配置的 consistency 級別),主分片節(jié)點才會向協(xié)調(diào)節(jié)點報告成功。這提供了數(shù)據(jù)的高可用性和容錯能力。
9. 響應(yīng)客戶端
協(xié)調(diào)節(jié)點收到主分片節(jié)點的成功響應(yīng)后,會向客戶端返回一個確認,通常包含索引名稱、文檔 ID、版本號以及操作結(jié)果(如 "result": "created")。
10. 后續(xù)持久化:刷寫(Flush)與段合并
為了數(shù)據(jù)的長期持久化,Elasticsearch 會定期執(zhí)行刷寫操作:
- Translog 刷寫:當 Translog 達到一定大小時(默認 512MB)或定期(默認 30 分鐘),會觸發(fā)一次刷寫。此時,內(nèi)存中所有未持久化的段會被完全寫入磁盤,同時清空 Translog。
- 段合并:由于頻繁刷新會產(chǎn)生大量小段,Elasticsearch 會在后臺自動合并小段為更大的段,優(yōu)化存儲和搜索性能,并刪除已刪除的文檔。
###
Elasticsearch 的 PUT 過程是一個分布式、多階段的數(shù)據(jù)處理與存儲流程。它巧妙地將數(shù)據(jù)路由、實時處理(映射、分析)、內(nèi)存緩沖、事務(wù)日志、刷新與刷寫機制,以及副本復(fù)制結(jié)合起來,在保證性能、可搜索性和可靠性的提供了強大的數(shù)據(jù)存儲支持服務(wù)。理解這一流程有助于更好地設(shè)計索引、調(diào)優(yōu)性能和診斷問題。